
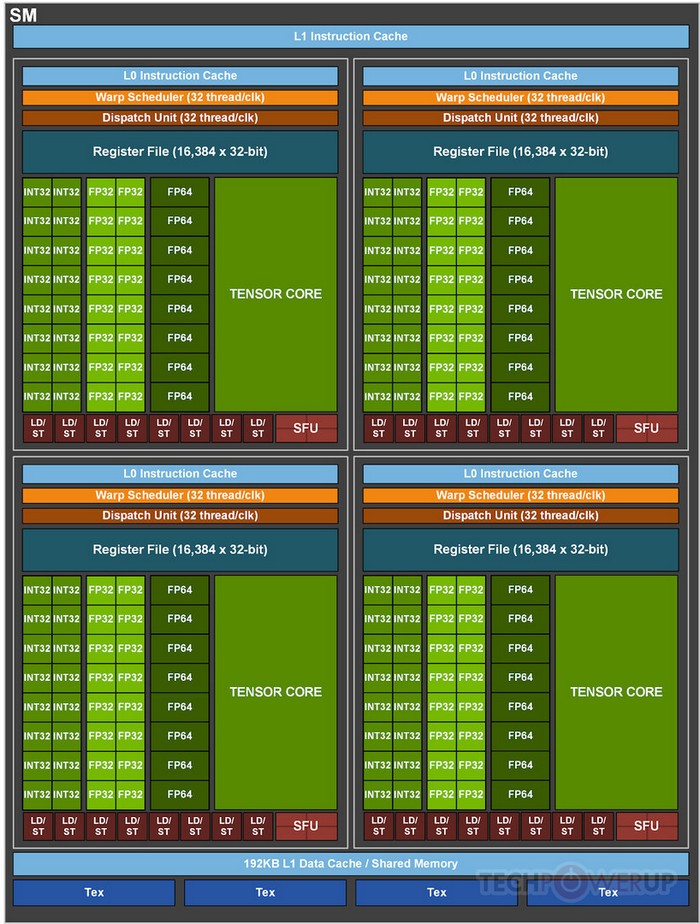
从官方给出的GA100核心构架图来看,GA100共有128组SM,因为每一个SM还是64个CUDA,所以完整的GA100一共是拥有8192个CUDA核心流处理器。不过,这次采用GA100打造的Tesla A100加速卡并非完整核心,被砍掉了20组SM,也就是108组SM,所以内包括6912个FP32 CUDA核心。不过需注意的是,它还有独立的3456个FP64(双精度)CUDA核心和432个Tensor Cores核心。
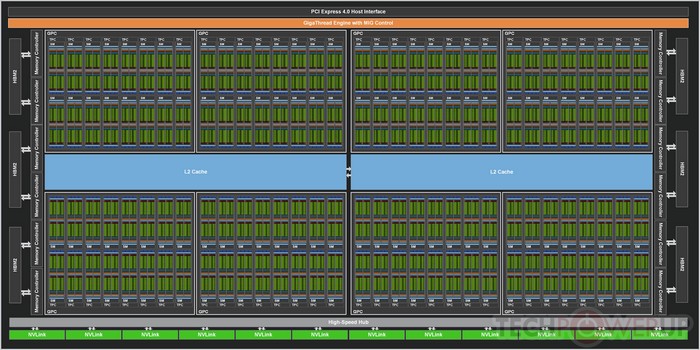
性能方面,单精度浮点计算能力可提供约19.5 TFLOPS,而双精度为9.7 TFLOPS算力。而在Tensor Float(TF32)单精度高达156 TFLOPS,这是因为新架构升级拥有第三代Tensor核心,可以让Tensor Cores在没有改动代码的情况下提高20倍的单精度性能。另外,新的Tensor Cores还加入了针对双精度浮点支持,相比Volta GV100性能提升2.5倍。
Tesla A100一共是配备了40GB超大容量HBM2E显存,拥有6144bit超级带宽,总带宽高达1.6TB/s。如果是NVLink技术双卡的话,能够提供最高600GB/s带宽,支持PCIe 4.0,最高数据传输速度提升到了64GB/s。NVIDIA还用NVIDIA A100打造了NVIDIA DGX AI系统,可用于数据分析,科学计算和云图形等,目前已经有18家服务商与其合作,比如百度云、亚马逊、戴尔、谷歌云、惠普、微软Azure和Orache等。
最后,有业内人士表示,Q3季度NVIDIA会推出基于安培架构的桌面消费级显卡~
消息来源:http://www.fashaoyou.net/Article/1543/95862.html

相关阅读
作者
1237篇 文章总数
6813963 总阅读量

推荐阅读
